SYNCAD: Cross Modal Diffusion Synchronized Yields from Narrative Cross Modal Audio and Data

Project Team : Aditya Vardhan – 121CS0055 & Madhav Kartheek – 121CS0051
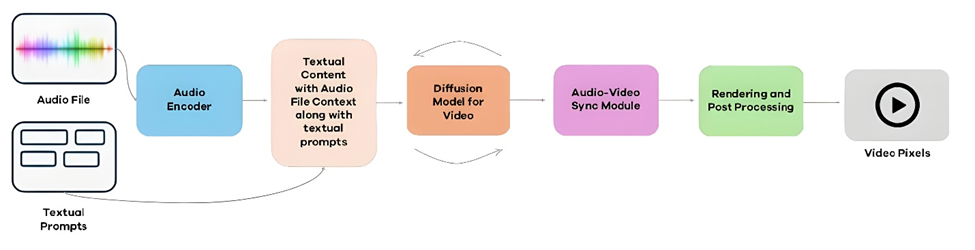
Diffusion models designed to generate videos from text or audio inputs face significant challenges. The primary issue arises from the difficulty in accurately mapping descriptive information (e.g., text descriptions, audio cues) into video content that is both temporally coherent and semantically aligned. Current audio-video generation models, like MM-Diffusions, struggle with integrating diverse input modalities, limiting their interactivity and context-awareness.
We propose the SYNCADE model, which incorporates textual prompts and audio scene analysis to enhance the generation of more interactive, contextually relevant, and diverse audio-video content for real-world applications. The challenge lies in creating cross-modal diffusion models that not only map the input description (text/audio) to a temporally consistent video but also ensure that the generated video is semantically faithful to the input prompt (audio/text).
Back